Problema actual
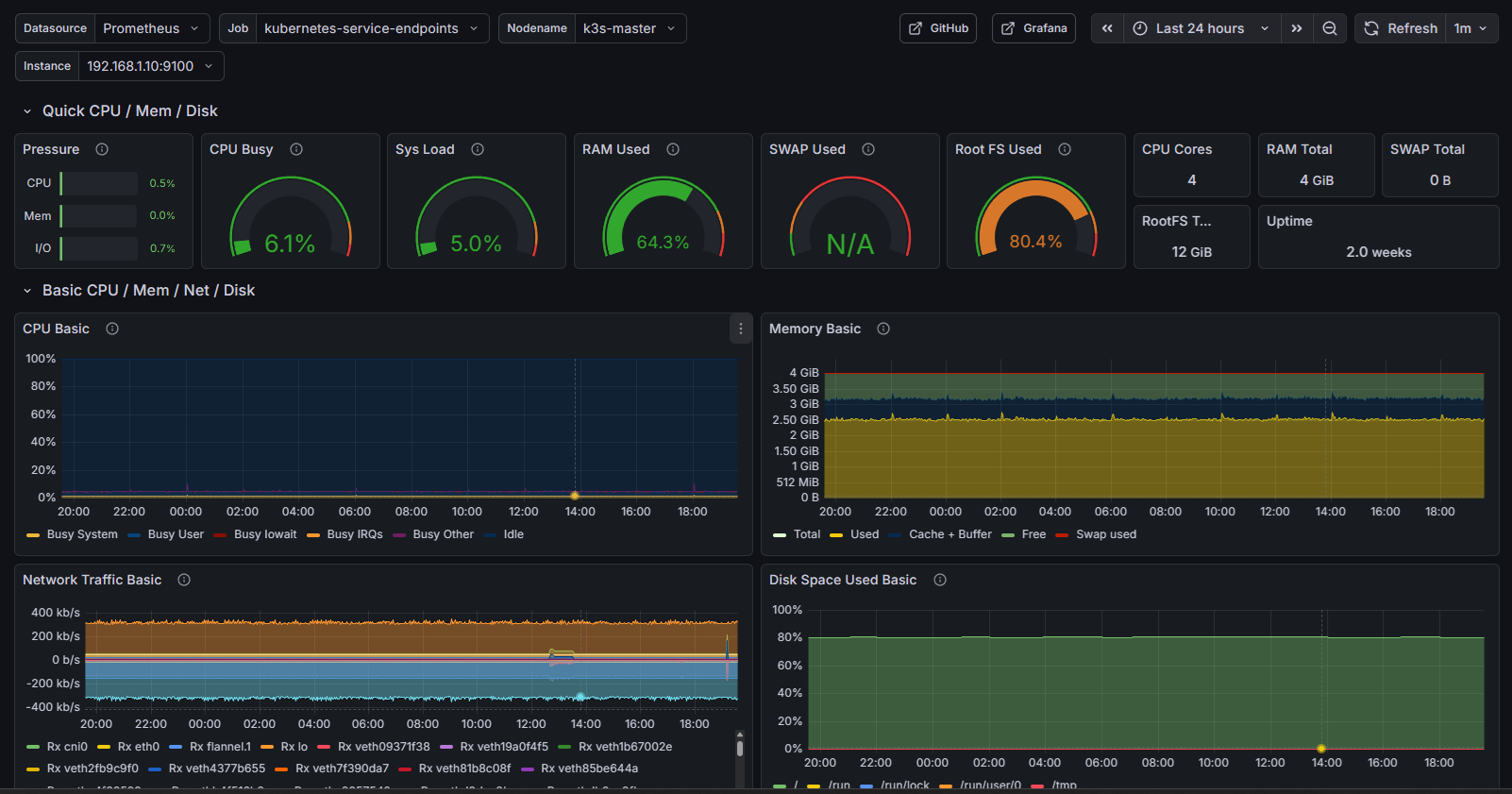
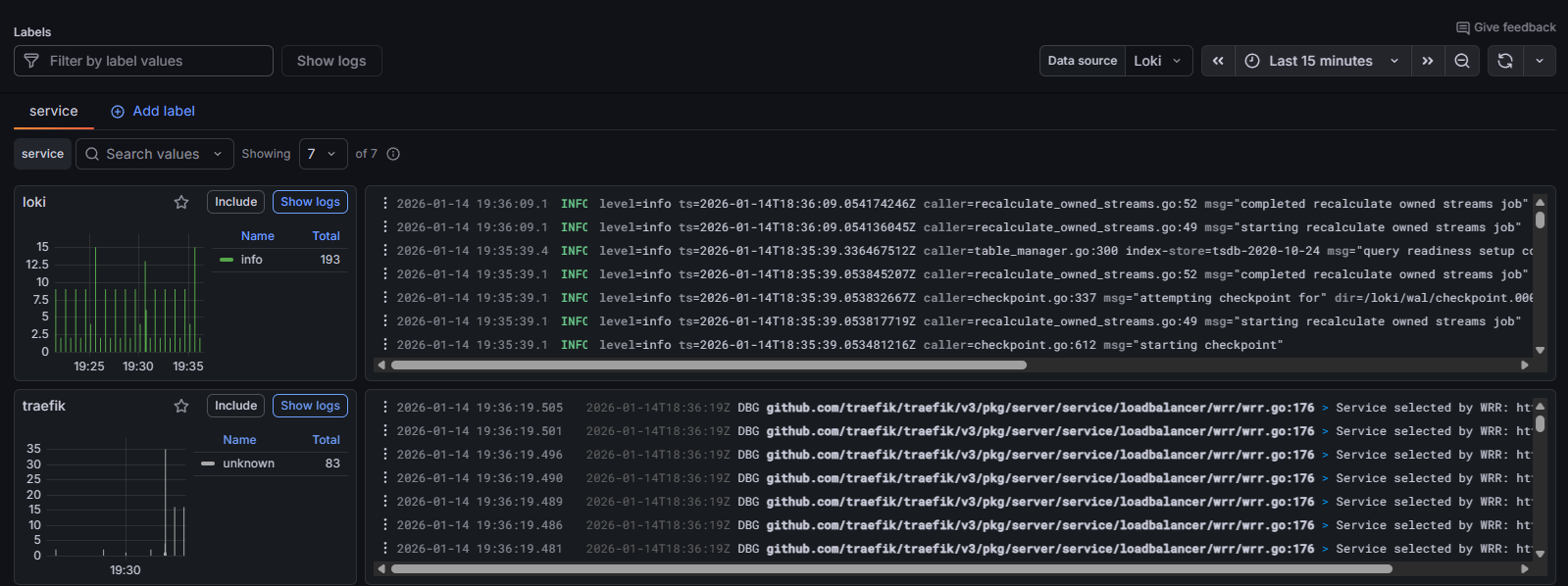
Ahora mismo, si ocurre algún problema con el servidor, no tenemos forma de detectarlo ni de monitorear su estado. Esto puede llevar a tiempos de inactividad prolongados y dificultades en la resolución de problemas.
Para solucionar este problema, necesitamos implementar un sistema de monitorización que nos permita detectar y responder rápidamente a cualquier fallo en el servidor. En la industria se suele optar por una de dos opciones: ELK stack (más robusta y con rodaje), o Grafana + Prometheus + Loki (una solución más moderna y eficiente y nativa a entornos contenerizados y cloud).
Yo opté por la segunda opción, ya que cubría todas mis necesidades consumiento menos recursos y siendo más simple de implementar.